
 HBase基础学习
HBase基础学习
# hbase shell
此时一个异常: org.apache.hadoop.hbase.PleaseHoldException: Master is initializing 原因:配置修改后,zk里的hbase表未删除 解决:https://blog.csdn.net/RONE321/article/details/99940862
扫描所有版本信息
scan 'student',{RAW=>TRUE,VERSIONS=>5}
创建表
create 'student','info'
已有表新建/删除列族
alter 'student','columnfamily2'
alter 'student',{NAME=>'info2',METHOD=>'delete'}
alter 'student',{NAME=>'info1',VERSIONS=>'3'}
查看表是否存在
exists 'student'
表是否不可用/可用
is_disabled 'student'
is_enabled 'student'
列出所有表
list
查看单个表
describe/desc 'student'
加入数据
put 'student',1,'info:id',100
修改表记录
put 'student',1,'info:name','abc'
查看表数据
scan 'student'
get 'student',1
get 'student',1,'info:id'
删除表记录
delete 'student',1,'info:name'
删除rowkey
deleteall 'student',1
清空表
truncate 'student'
删除表
1.disable 'student'
2.drop 'student'
停用表
disable 'student'
表可用
enable 'student'
命名空间操作
list_namespace
create_namespace 'bigdata'
create 'bigdata:student','info'
# hbase架构原理
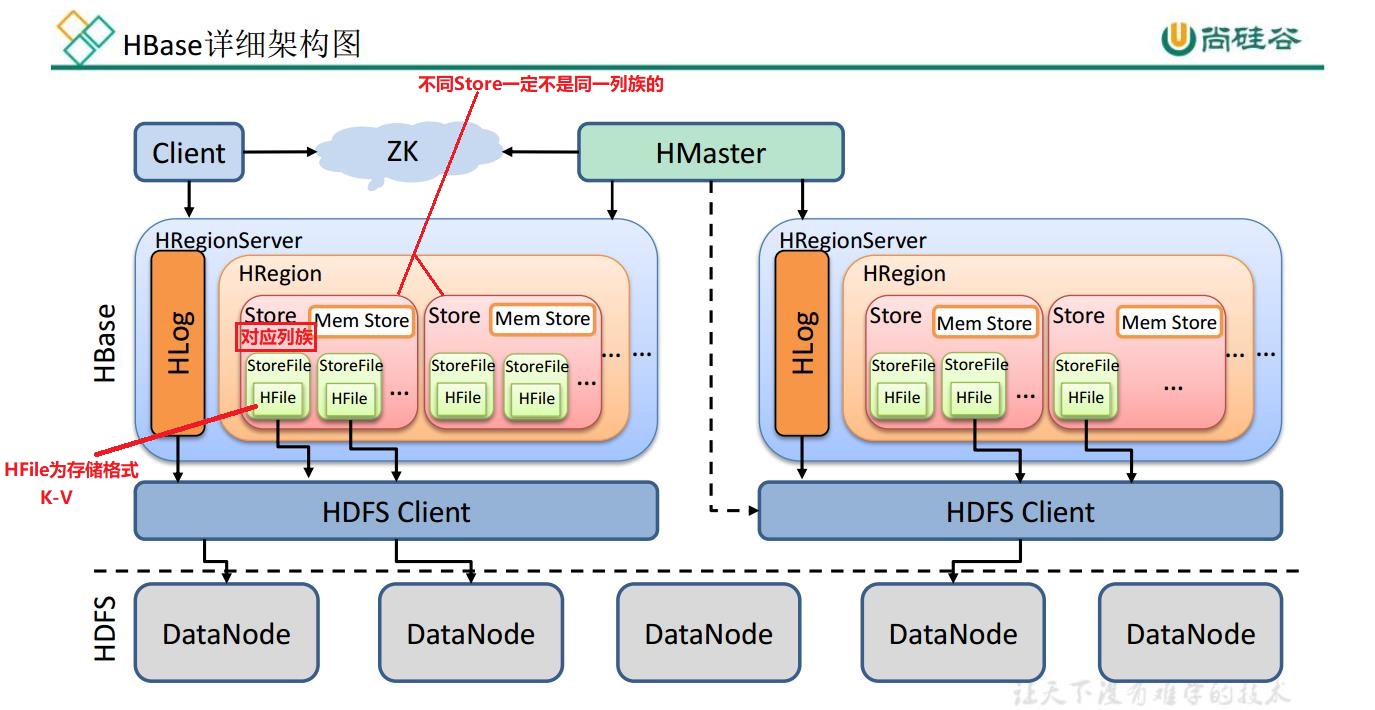
1) StoreFile
保存实际数据的物理文件, StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
2) MemStore
写缓存, 由于 HFile 中的数据要求是有序的, 所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
3) WAL
由于数据要经 MemStore 排序后才能刷写到 HFile, 但把数据保存在内存中会有很高的
概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建
# hbase写流程
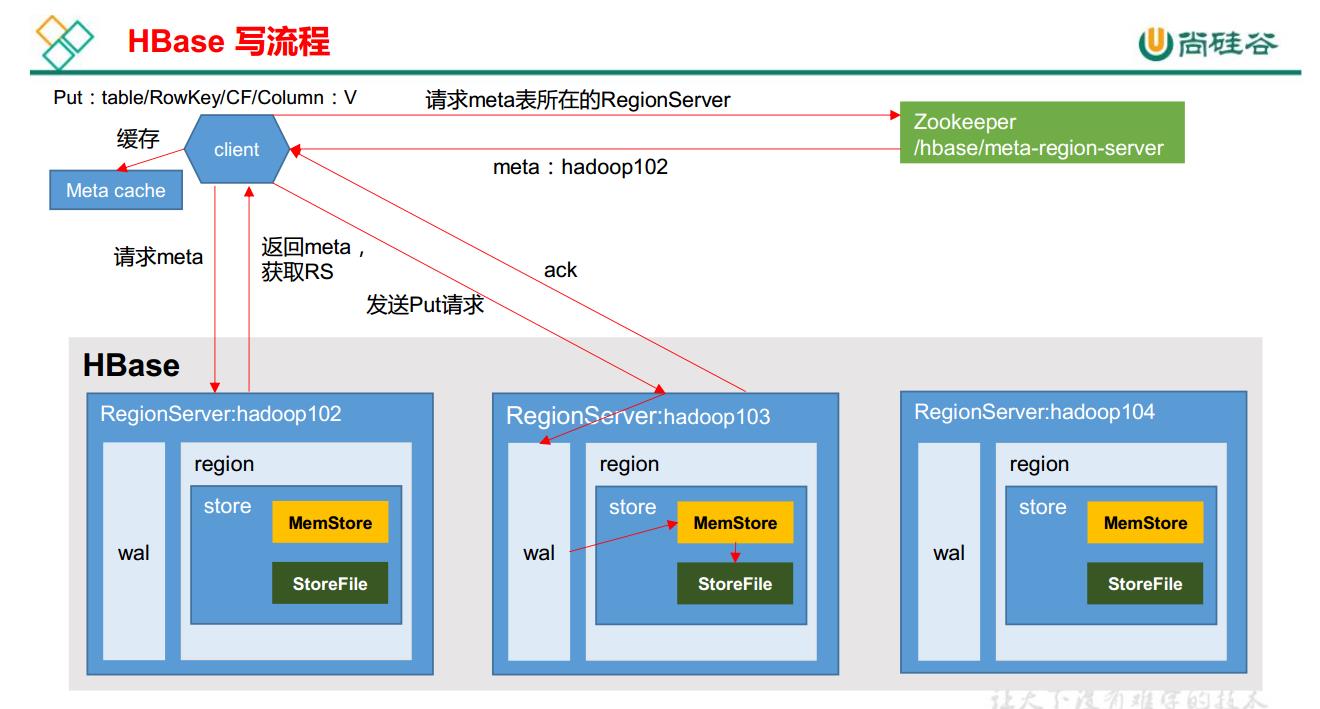
1) Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7) 等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
# hbase MemStore Flush
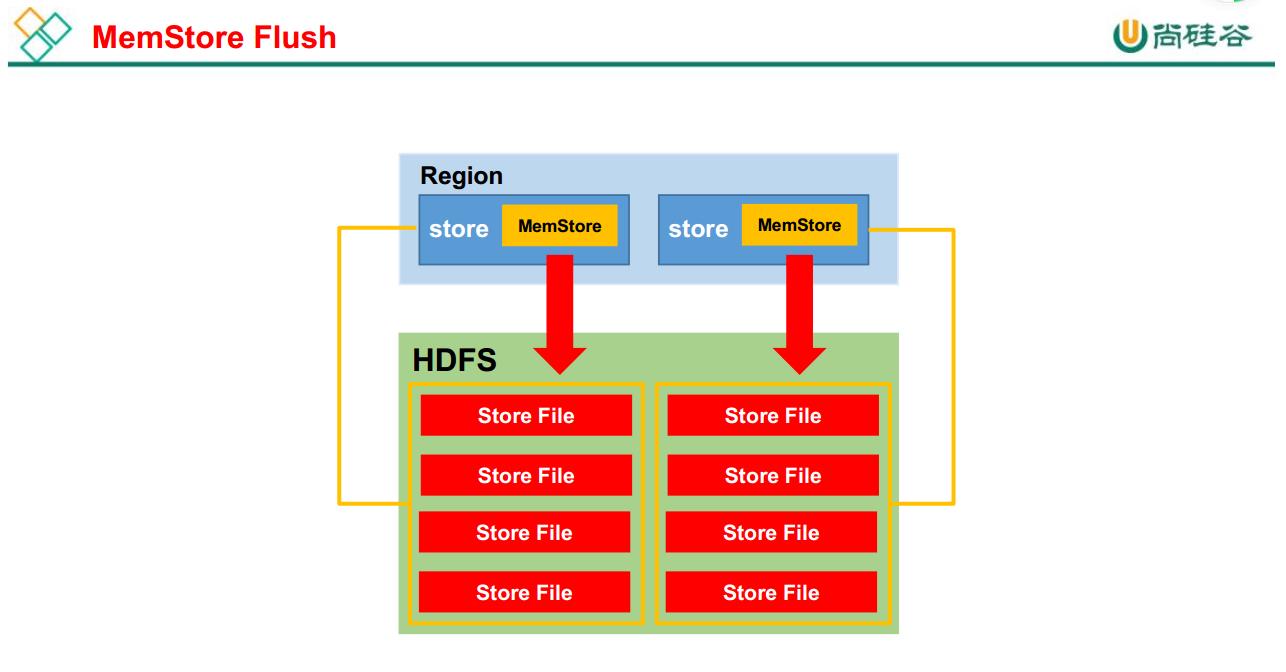
MemStore 刷写时机:
1.当某个 memstroe 的大小达到了 hbase.hregion.memstore.flush.size(默认值 128M) ,
其所在 region 的所有 memstore 都会刷写。
当 memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值 128M)
* hbase.hregion.memstore.block.multiplier(默认值 4)
时,会阻止继续往该 memstore 写数据。
2.当 region server 中 memstore 的总大小达到
java_heapsize
*hbase.regionserver.global.memstore.size(默认值 0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95) ,
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server
中所有 memstore 的总大小减小到上述值以下。
当 region server 中 memstore 的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)
时,会阻止继续往所有的 memstore 写数据。
3. 到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行
配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时) 。
4.当 WAL 文件的数量超过 hbase.regionserver.max.logs, region 会按照时间顺序依次进
行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,
现无需手动设置, 最大值为 32)。
# hbase读流程
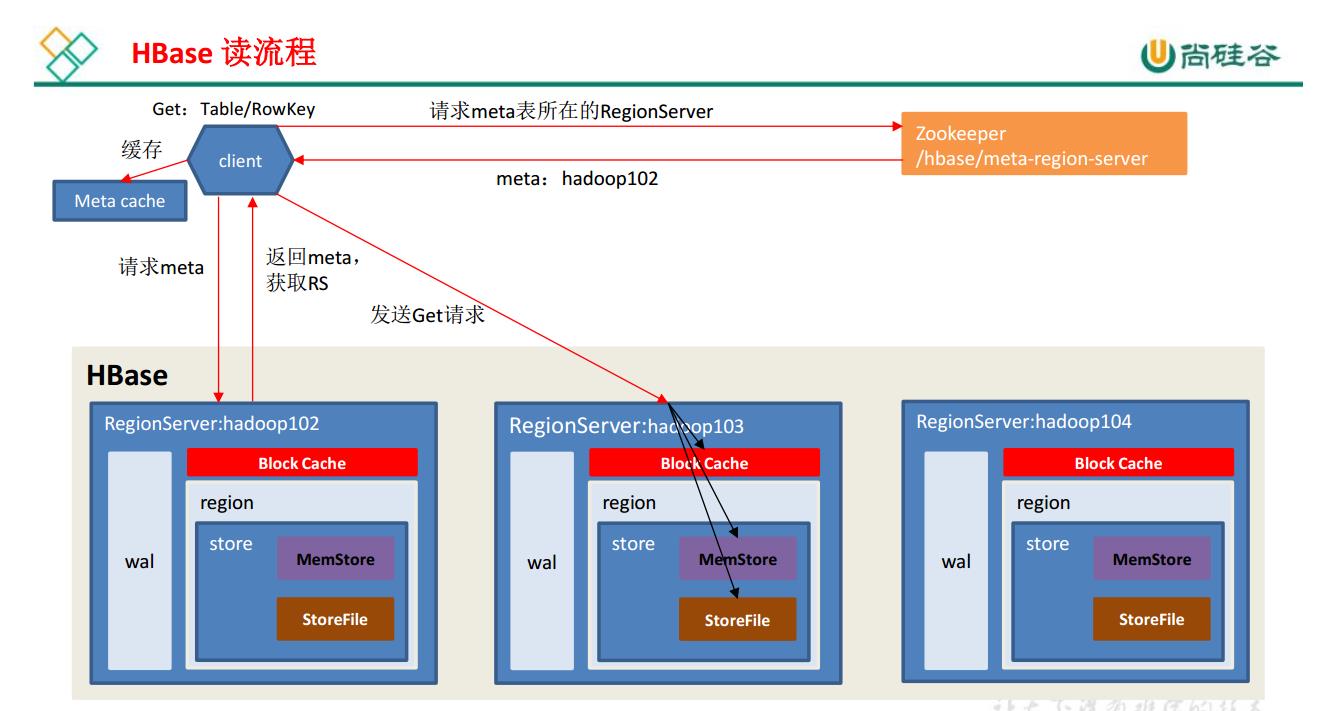
1) Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4) 分别在 Block Cache(读缓存), MemStore 和 Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block, HFile 数据存储单元,默认大小为 64KB)缓存到
Block Cache。
6) 将合并后的最终结果返回给客户端。
# StoreFile Compaction
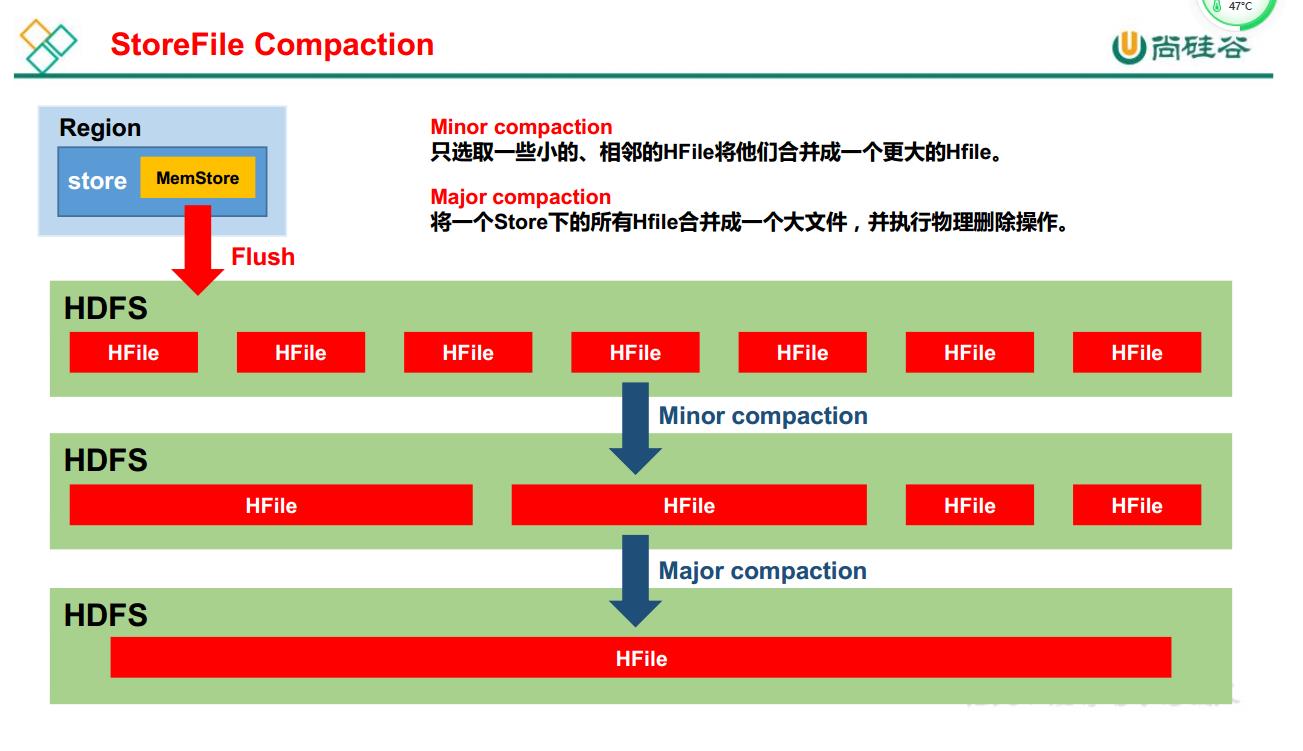
由于 memstore每次刷写都会生成一个新的 HFile,且同一个字段的不同版本(timestamp)
和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction
会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期和删除的数据。
# Region Split

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入, Region 会自动进
行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,
HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
1.当 1个 region中的某个 Store下所有 StoreFile的总大小超过 hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。
2. 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过 Min(R^2 *
"hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"), 该 Region 就会进行拆分,其中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
表预分区
HBase预分区
概念:
HBase表被创建时,只有1个Region,当一个Region过大达到默认的阈值时(默认10GB大小),HBase中该Region将会进行split,分裂为2个Region,以此类推。
表在进行split的时候,会耗费大量的资源,频繁的分区对HBase的性能有巨大的影响。
所以,HBase提供了预分区功能,即用户可以在创建表的时候对表按照一定的规则分区。
作用:
避免HBase经常split,产生不必要的资源消耗,提高HBase的性能。
预分区的方法:
1.HBase Shell
2.HBase Shell(通过读取split文件)
3.HBase Java API
# 代码Api
package com.hrbu.test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.NamespaceExistException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptor;
import org.apache.hadoop.hbase.client.ColumnFamilyDescriptorBuilder;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.client.TableDescriptor;
import org.apache.hadoop.hbase.client.TableDescriptorBuilder;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.CompareFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.KeyOnlyFilter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.filter.RandomRowFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.regionserver.NoSuchColumnFamilyException;
import org.apache.hadoop.hbase.util.Bytes;
/**
* DDL: 1.判断表是否存在 2.创建表 3.创建命名空间 4.删除表
* DML: 5.插入数据 6.查数据(get) 7.查数据(scan) 8.删除数据
*/
public class TestApi {
public static Connection connect = null;
public static Admin admin = null;
static {
try {
// 1. 获取配置文件信息(使用 HBaseConfiguration 的单例方法实例化)
Configuration conf = HBaseConfiguration.create();
//conf.set("hbase.zookeeper.quorum", "hadoop101,hadoop102,hadoop103");
conf.set("hbase.zookeeper.quorum", "hadoop1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
// 2. 创建连接对象
connect = ConnectionFactory.createConnection(conf);
// 3. 获取管理员对象
admin = connect.getAdmin();
} catch (IOException e) {
// TODO Auto-generated catch block
System.out.println("创建hbase连接对象异常");
e.printStackTrace();
}
}
// 关闭资源和连接
public static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
System.out.println("admin关闭异常");
e.printStackTrace();
}
}
if (connect != null) {
try {
connect.close();
} catch (IOException e) {
System.out.println("hbase连接对象关闭异常");
e.printStackTrace();
}
}
}
// 1.判断表是否存在
public static void is_Exists(String tableName) throws IOException {
if (admin.tableExists(TableName.valueOf(tableName))) {
System.out.println(tableName + "表已经存在");
} else {
System.out.println(tableName + "表不存在");
}
}
// 2.创建表
public static void create_Table(String tableName) throws IOException {
TableName tableNameTemp = TableName.valueOf(tableName);
if (admin.tableExists(tableNameTemp)) {
System.out.println(tableName + "表已经存在");
} else {
// 4.通过表实例来执行表结构信息
TableDescriptorBuilder tableBuilder = TableDescriptorBuilder.newBuilder(tableNameTemp);
// 列族
ColumnFamilyDescriptor info1 = ColumnFamilyDescriptorBuilder.of("info1");
ColumnFamilyDescriptor info2 = ColumnFamilyDescriptorBuilder.of("info2");
ColumnFamilyDescriptor info3 = ColumnFamilyDescriptorBuilder.of("info3");
List<ColumnFamilyDescriptor> cfList = new ArrayList<ColumnFamilyDescriptor>();
cfList.add(info1);
cfList.add(info2);
cfList.add(info3);
tableBuilder.setColumnFamilies(cfList);
// 5.构建表描述
TableDescriptor tableDesc = tableBuilder.build();
admin.createTable(tableDesc);
System.out.println(tableName + "\t表创建成功");
}
}
// 3.创建命名空间
public static void create_NameSpace(String nameSpace) {
// 创建命名空间描述器
NamespaceDescriptor descriptor = NamespaceDescriptor.create(nameSpace).build();
//创建命名空间
try {
admin.createNamespace(descriptor);
} catch(NamespaceExistException e) {
System.out.println(nameSpace + "命名空间已存在");
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("--我会被执行吗--");
}
// 4.删除表
public static void drop_Table(String tableName) throws IOException {
TableName tableNameTemp = TableName.valueOf(tableName);
if (admin.tableExists(tableNameTemp)) {
admin.disableTable(tableNameTemp);
admin.deleteTable(tableNameTemp);
System.out.println("表" + tableName + "删除成功! ");
} else {
System.out.println("表" + tableName + "不存在! ");
}
}
// 5.插入数据
public static void put_Data(String tableName, String rowKey, String columnFamily, String column, String value) {
Table table = null;
try {
table = connect.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
table.put(put);
} catch(NoSuchColumnFamilyException e){
System.out.println("异常:没有此列族");
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(table!=null) {
table.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("数据插入成功");
}
// 6.查数据(get)
public static void get_Data(String tableName, String rowKey, String columnFamily, String column) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
//get.addFamily(Bytes.toBytes(columnFamily));
get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));
Result result = table.get(get);
Cell[] cells = result.rawCells();
System.out.println(tableName + "--" + rowKey + "--" + columnFamily + "--" + column + ":");
print_Cells2(cells);
table.close();
}
public static void get_Data(String tableName, String rowKey, String columnFamily) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
get.addFamily(Bytes.toBytes(columnFamily));
Result result = table.get(get);
Cell[] cells = result.rawCells();
System.out.println(tableName + "--" + rowKey + "--" + columnFamily + ":");
print_Cells2(cells);
table.close();
}
public static void get_Data(String tableName, String rowKey) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
Result result = table.get(get);
Cell[] cells = result.rawCells();
System.out.println(tableName + "--" + rowKey + ":");
print_Cells2(cells);
table.close();
}
// 打印单元格信息
private static void print_Cells(Cell[] cells) {
for (Cell tempCell : cells) {
System.out.println(Bytes.toString(CellUtil.cloneRow(tempCell))
+ "\t\tcolumn=" + Bytes.toString(CellUtil.cloneFamily(tempCell)) + ":" + Bytes.toString(CellUtil.cloneQualifier(tempCell))
+ ",timestamp=" + tempCell.getTimestamp()
+ ", value=" + Bytes.toString(CellUtil.cloneValue(tempCell)) );
}
}
// 打印单元格信息
private static void print_Cells2(Cell[] cells) {
StringBuilder sb = new StringBuilder();
for (Cell cell : cells) {
String column = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());
String value = Bytes.toString(cell.getValueArray(),cell.getValueOffset(),cell.getValueLength());
sb.append(column).append(":").append(value).append(";\t");
}
System.out.println(sb.toString());
}
// 7.查数据(scan)
public static void scan_Data(String tableName) {
Table table = null;
try {
table = connect.getTable(TableName.valueOf(tableName));
ResultScanner results = table.getScanner(new Scan());
System.out.println(tableName + "表\nROW\t\tCOLUMN+CELL");
for (Result result : results) {
Cell[] cells = result.rawCells();
print_Cells(cells);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(table!=null) {
table.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
// 7.2 查数据(scan + filter)
public static void filter_Data(String tableName, Filter filter, int limit) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
Scan scan = new Scan().setFilter(filter).setLimit(limit);
ResultScanner resultScan = table.getScanner(scan);
System.out.println(tableName + "表(filter)\nROW\t\tCOLUMN+CELL");
for (Result result : resultScan) {
Cell[] cells = result.rawCells();
print_Cells(cells);
}
table.close();
}
// 8. 删除多行数据
public static void delete_Data(String tableName, String... rows) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
//Delete delete = new Delete(Bytes.toBytes(rowKey));
List<Delete> deleteList = new ArrayList<Delete>();
for (String row:rows) {
Delete delete = new Delete(Bytes.toBytes(row));
deleteList.add(delete);
}
table.delete(deleteList);
table.close();
System.out.println("删除成功");
}
// 8.1 删除单元格(Cell)数据
public static void delete_Cell(String tableName, String rowKey, String columnFamily, String column ) throws IOException {
Table table = connect.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column)); //删除最后一版本
//delete.addColumns(Bytes.toBytes(columnFamily), Bytes.toBytes(column)); //删除所有版本
table.delete(delete);
table.close();
}
public static void main(String[] args) throws IOException {
System.out.println("============================start=========================");
// 1.判断表是否存在
//is_Exists("student");
// 3.创建命名空间
//create_NameSpace("std");
// 2.创建表
//create_Table("std:stu");
// 4.删除表
//drop_Table("std:stu");
// 5.插入数据
//put_Data("std:stu", "1003", "info1", "addr", "beijing");
//put_Data("std:stu", "1004", "info1", "sex", "男");
//put_Data("std:stu", "1005", "info1", "class", "2");
// 6.查数据(get)
get_Data("std:stu", "1002");
get_Data("std:stu", "1002", "info1");
// 7.查数据(scan)
scan_Data("std:stu");
// 7.1 查数据(scan + filter)
//filter_Data("std:stu", new PrefixFilter(Bytes.toBytes("100")), 10); //筛选出行键以row为前缀的所有的行
//filter_Data("std:stu", new RandomRowFilter((float) 0.2), 10); //按照一定的几率(<=0会过滤掉所有的行,>=1会包含所有的行)来返回随机的结果集
//filter_Data("std:stu", new KeyOnlyFilter(), 10); // 返回所有的行,但值全是空
// 筛选出匹配的所有的行
filter_Data("std:stu", new RowFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("1002"))), 10);
// 8. 删除多行数据数据
//delete_Data("std:stu", "1003","1004");
// 8.1删除单元格数据
//delete_Cell("std:stu", "1005", "info1", "name");
scan_Data("std:stu");
System.out.println("============================end==========================");
// end:关闭资源和连接
close();
}
}
编辑 (opens new window)
上次更新: 2025/03/28, 16:47:15